 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESOM: Efficiently Understanding Streaming Video Anomalies with Open-world Dynamic Definitions
Apr 09, 2026Open-world video anomaly detection (OWVAD) aims to detect and explain abnormal events under different anomaly definitions, which is important for applications such as intelligent surveillance and live-streaming content moderation. Recent MLLM-based methods have shown promising open-world generalization, but still suffer from three major limitations: inefficiency for practical deployment, lack of streaming processing adaptation, and limited support for dynamic anomaly definitions in both modeling and evaluation. To address these issues, this paper proposes ESOM, an efficient streaming OWVAD model that operates in a training-free manner. ESOM includes a Definition Normalization module to structure user prompts for reducing hallucination, an Inter-frame-matched Intra-frame Token Merging module to compress redundant visual tokens, a Hybrid Streaming Memory module for efficient causal inference, and a Probabilistic Scoring module that converts interval-level textual outputs into frame-level anomaly scores. In addition, this paper introduces OpenDef-Bench, a new benchmark with clean surveillance videos and diverse natural anomaly definitions for evaluating performance under varying conditions. Extensive experiments show that ESOM achieves real-time efficiency on a single GPU and state-of-the-art performance in anomaly temporal localization, classification, and description generation. The code and benchmark will be released at https://github.com/Kamino666/ESOM_OpenDef-Bench.
Kirchhoff-Inspired Neural Networks for Evolving High-Order Perception
Mar 25, 2026Deep learning architectures are fundamentally inspired by neuroscience, particularly the structure of the brain's sensory pathways, and have achieved remarkable success in learning informative data representations. Although these architectures mimic the communication mechanisms of biological neurons, their strategies for information encoding and transmission are fundamentally distinct. Biological systems depend on dynamic fluctuations in membrane potential; by contrast, conventional deep networks optimize weights and biases by adjusting the strengths of inter-neural connections, lacking a systematic mechanism to jointly characterize the interplay among signal intensity, coupling structure, and state evolution. To tackle this limitation, we propose the Kirchhoff-Inspired Neural Network (KINN), a state-variable-based network architecture constructed based on Kirchhoff's current law. KINN derives numerically stable state updates from fundamental ordinary differential equations, enabling the explicit decoupling and encoding of higher-order evolutionary components within a single layer while preserving physical consistency, interpretability, and end-to-end trainability. Extensive experiments on partial differential equation (PDE) solving and ImageNet image classification validate that KINN outperforms state-of-the-art existing methods.
Unbiased Dynamic Pruning for Efficient Group-Based Policy Optimization
Mar 04, 2026Group Relative Policy Optimization (GRPO) effectively scales LLM reasoning but incurs prohibitive computational costs due to its extensive group-based sampling requirement. While recent selective data utilization methods can mitigate this overhead, they could induce estimation bias by altering the underlying sampling distribution, compromising theoretical rigor and convergence behavior. To address this limitation, we propose Dynamic Pruning Policy Optimization (DPPO), a framework that enables dynamic pruning while preserving unbiased gradient estimation through importance sampling-based correction. By incorporating mathematically derived rescaling factors, DPPO significantly accelerates GRPO training without altering the optimization objective of the full-batch baseline. Furthermore, to mitigate the data sparsity induced by pruning, we introduce Dense Prompt Packing, a window-based greedy strategy that maximizes valid token density and hardware utilization. Extensive experiments demonstrate that DPPO consistently accelerates training across diverse models and benchmarks. For instance, on Qwen3-4B trained on MATH, DPPO achieves 2.37$\times$ training speedup and outperforms GRPO by 3.36% in average accuracy across six mathematical reasoning benchmarks.
SesaHand: Enhancing 3D Hand Reconstruction via Controllable Generation with Semantic and Structural Alignment
Feb 28, 2026Recent studies on 3D hand reconstruction have demonstrated the effectiveness of synthetic training data to improve estimation performance. However, most methods rely on game engines to synthesize hand images, which often lack diversity in textures and environments, and fail to include crucial components like arms or interacting objects. Generative models are promising alternatives to generate diverse hand images, but still suffer from misalignment issues. In this paper, we present SesaHand, which enhances controllable hand image generation from both semantic and structural alignment perspectives for 3D hand reconstruction. Specifically, for semantic alignment, we propose a pipeline with Chain-of-Thought inference to extract human behavior semantics from image captions generated by the Vision-Language Model. This semantics suppresses human-irrelevant environmental details and ensures sufficient human-centric contexts for hand image generation. For structural alignment, we introduce hierarchical structural fusion to integrate structural information with different granularity for feature refinement to better align the hand and the overall human body in generated images. We further propose a hand structure attention enhancement method to efficiently enhance the model's attention on hand regions. Experiments demonstrate that our method not only outperforms prior work in generation performance but also improves 3D hand reconstruction with the generated hand images.
AMLRIS: Alignment-aware Masked Learning for Referring Image Segmentation
Feb 26, 2026Referring Image Segmentation (RIS) aims to segment an object in an image identified by a natural language expression. The paper introduces Alignment-Aware Masked Learning (AML), a training strategy to enhance RIS by explicitly estimating pixel-level vision-language alignment, filtering out poorly aligned regions during optimization, and focusing on trustworthy cues. This approach results in state-of-the-art performance on RefCOCO datasets and also enhances robustness to diverse descriptions and scenarios
UrbanGS: A Scalable and Efficient Architecture for Geometrically Accurate Large-Scene Reconstruction
Feb 02, 2026While 3D Gaussian Splatting (3DGS) enables high-quality, real-time rendering for bounded scenes, its extension to large-scale urban environments gives rise to critical challenges in terms of geometric consistency, memory efficiency, and computational scalability. To address these issues, we present UrbanGS, a scalable reconstruction framework that effectively tackles these challenges for city-scale applications. First, we propose a Depth-Consistent D-Normal Regularization module. Unlike existing approaches that rely solely on monocular normal estimators, which can effectively update rotation parameters yet struggle to update position parameters, our method integrates D-Normal constraints with external depth supervision. This allows for comprehensive updates of all geometric parameters. By further incorporating an adaptive confidence weighting mechanism based on gradient consistency and inverse depth deviation, our approach significantly enhances multi-view depth alignment and geometric coherence, which effectively resolves the issue of geometric accuracy in complex large-scale scenes. To improve scalability, we introduce a Spatially Adaptive Gaussian Pruning (SAGP) strategy, which dynamically adjusts Gaussian density based on local geometric complexity and visibility to reduce redundancy. Additionally, a unified partitioning and view assignment scheme is designed to eliminate boundary artifacts and optimize computational load. Extensive experiments on multiple urban datasets demonstrate that UrbanGS achieves superior performance in rendering quality, geometric accuracy, and memory efficiency, providing a systematic solution for high-fidelity large-scale scene reconstruction.
Noise-Robust Tiny Object Localization with Flows
Jan 02, 2026Despite significant advances in generic object detection, a persistent performance gap remains for tiny objects compared to normal-scale objects. We demonstrate that tiny objects are highly sensitive to annotation noise, where optimizing strict localization objectives risks noise overfitting. To address this, we propose Tiny Object Localization with Flows (TOLF), a noise-robust localization framework leveraging normalizing flows for flexible error modeling and uncertainty-guided optimization. Our method captures complex, non-Gaussian prediction distributions through flow-based error modeling, enabling robust learning under noisy supervision. An uncertainty-aware gradient modulation mechanism further suppresses learning from high-uncertainty, noise-prone samples, mitigating overfitting while stabilizing training. Extensive experiments across three datasets validate our approach's effectiveness. Especially, TOLF boosts the DINO baseline by 1.2% AP on the AI-TOD dataset.
AnchorDS: Anchoring Dynamic Sources for Semantically Consistent Text-to-3D Generation
Nov 12, 2025Optimization-based text-to-3D methods distill guidance from 2D generative models via Score Distillation Sampling (SDS), but implicitly treat this guidance as static. This work shows that ignoring source dynamics yields inconsistent trajectories that suppress or merge semantic cues, leading to "semantic over-smoothing" artifacts. As such, we reformulate text-to-3D optimization as mapping a dynamically evolving source distribution to a fixed target distribution. We cast the problem into a dual-conditioned latent space, conditioned on both the text prompt and the intermediately rendered image. Given this joint setup, we observe that the image condition naturally anchors the current source distribution. Building on this insight, we introduce AnchorDS, an improved score distillation mechanism that provides state-anchored guidance with image conditions and stabilizes generation. We further penalize erroneous source estimates and design a lightweight filter strategy and fine-tuning strategy that refines the anchor with negligible overhead. AnchorDS produces finer-grained detail, more natural colours, and stronger semantic consistency, particularly for complex prompts, while maintaining efficiency. Extensive experiments show that our method surpasses previous methods in both quality and efficiency.
MedFact-R1: Towards Factual Medical Reasoning via Pseudo-Label Augmentation
Sep 18, 2025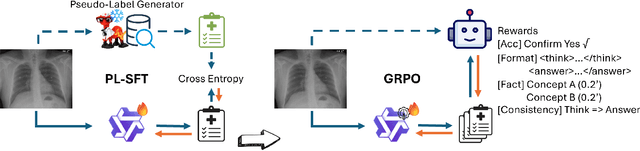
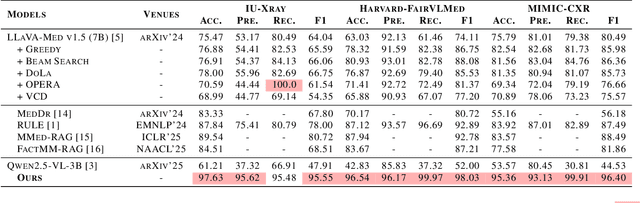

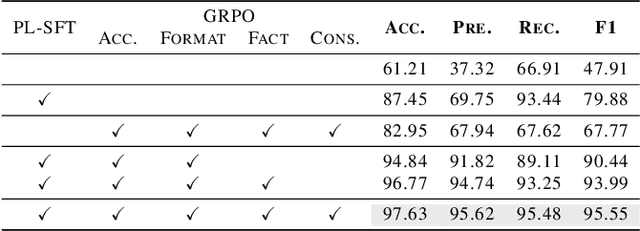
Ensuring factual consistency and reliable reasoning remains a critical challenge for medical vision-language models. We introduce MEDFACT-R1, a two-stage framework that integrates external knowledge grounding with reinforcement learning to improve the factual medical reasoning. The first stage uses pseudo-label supervised fine-tuning (SFT) to incorporate external factual expertise; while the second stage applies Group Relative Policy Optimization (GRPO) with four tailored factual reward signals to encourage self-consistent reasoning. Across three public medical QA benchmarks, MEDFACT-R1 delivers up to 22.5% absolute improvement in factual accuracy over previous state-of-the-art methods. Ablation studies highlight the necessity of pseudo-label SFT cold start and validate the contribution of each GRPO reward, underscoring the synergy between knowledge grounding and RL-driven reasoning for trustworthy medical AI. Codes are released at https://github.com/Garfieldgengliang/MEDFACT-R1.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.